 |
BMe Research Grant |

|

BME, Doctoral School for Computer Sciences
Department of Telecommunications and Media Informatics
Supervisor: Dr. Géza NÉMETH
Statistical parametric speech synthesis with irregular voice models
Introducing the research area
Research on statistical parametric speech synthesis contributes to making human-computer interaction better. This plays an important role in the formation of information society. Most speech technology methods have been developed for processing ideal speech, and until recently little efforts have been spent on different cases (like irregular vibration of the vocal folds) in speech synthesis. Irregular phonation (perceptually creaky, rough voice) occurs in natural speech. Some speakers use this voice quality frequently in everyday speech to express emotions, mark sentence boundaries or show the current mood. The modeling of this phenomenon contributes to the development of a more natural human-computer interaction.
Brief introduction of the research place
Speech communication research and development started in 1969 at the predecessor of the Department of Telecommunications and Media Informatics. The Speech Technology Laboratory, led by Dr. Géza Németh, has outstanding results and decade-long experience in speech research and industrial applications of speech technology. This research group has numerous publications and applications in the field of Hungarian text-to-speech (TTS) synthesis.
History and context of the research
Continuous research on human-computer interaction is required during the formation of the information society, because computer and machine systems have to be made accessible at the broadest level . A good example for this is the appearance of Apple Siri. The goal of speech synthesis is to convert written text to speech, which is as similar to human speech as possible. State-of-the-art systems use statistical parametric methods, which apply machine learning technique for the representation of speech properties [1]. Hidden Markov-models (HMM) are most frequently used for this purpose, resulting in an almost natural synthesized speech that reminds of the original speaker [2].
Most models were developed for regular speech, based on the assumption that the vibration of vocal folds is quasi-periodic during voiced phonation [3]. This holds in most cases, but for shorter or longer periods of time, this vibration might become irregular: fluctuations appear in the period-by-period amplitude and / or fundamental frequency (F0) [4]. Fig. 1 shows the difference between regular and irregular speech: in the regular version of the word “cipő” the sound “ő” contains smooth periods, while in the irregular version strong amplitude attenuations can be seen in the range denoted by an arrow. Perceptually this means a rough, creaky voice, and can occur in up to 15% of voiced speech, therefore, the phenomenon is by far not negligible [5]. The proper modeling of irregular voice in speech synthesis can contribute to the development of personalized, expressive and more natural systems.
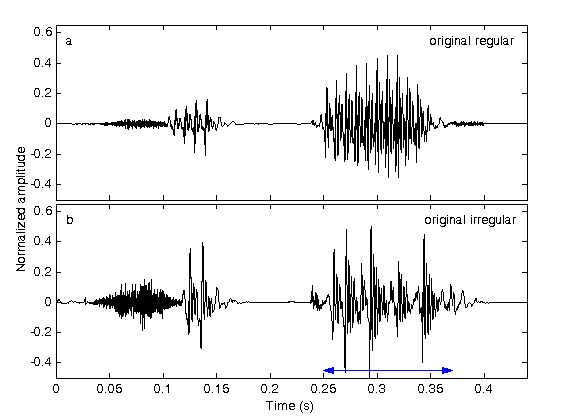
Fig. 1: Voiced speech with regular and irregular phonation: waveforms of the two versions of the word “cipő”. Horizontal arrow shows the duration of irregular voice.
The research goal, open questions
Scientific literature describes methods for the detection of irregular phonation [5], [6], regular-irregular transformation [3], [7], [8]. In statistical parametric speech synthesis, there have only been initial studies in this field [9], [10], [11].
The main ideas behind the methods of Silén et al. in HMM-based speech synthesis is the use robust F0 measure with reliable voicing decision in order to remove any irregular sections from synthesized speech [9]. This way the creaky voice characteristics of the original speaker are totally removed in synthesized speech, and the methods do not deal with reconstructing the correct timbre. Drugman et al. extend the DSM model [12] and showed with analysis-synthesis experiments that secondary impulses can properly model irregular speech [10]. Next, Raitio et al. integrated the extended model into HMM-based speech synthesis [11]. However, this recent study found that only a small proportion of listeners perceived the samples from the new system better.
Irregular phonation occurs in natural communication, too, and certain speakers use this often in everyday speech for expressing emotions, marking sentence endings or showing current mood [5], [12]. In our research we extend statistical parametric speech synthesis with irregular voice models, and investigate the extent this helps human-computer interaction sound more natural. For this, we propose two alternative methods to model irregular phonation, and check the results in subjective listening tests and acoustic experiments.
Methodology
In this research we extend the known and widely applied methods of speech technology with new algorithms. Statistical parametric speech synthesis does not manipulate the speech waveforms directly, but the speech signal is decomposed to parameters, which are fed to a machine learning algorithm. After machine learning phase, speech is generated back in the synthesis phase from the parameters.
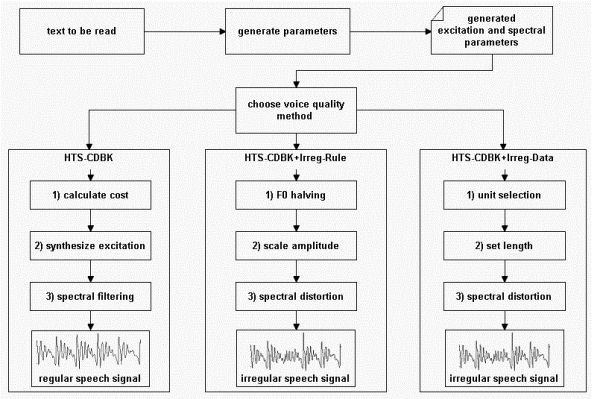
Fig. 2: Schematic functions of the regular voice model and the two new irregular voice models within speech synthesis.
New speech representation in statistical parametric speech synthesis
We created a new algorithm for the decomposition of speech to parameters [C1]. In the analysis phase, a codebook is constructed containing pitch-synchronous frames from the speech excitation signal. It represents speech with excitation and spectral parameter sequences instead of the raw waveform. With the conscious modification of the parameters it is possible to change the intonation and voice quality of original speech, thus the perceived roughness can be modified as well. Eventually, speech waveform can be reconstructed from the modified parameters[C1].
The above analysis-synthesis method was integrated into the hidden Markov-model based speech synthesizer [J1], which later was used as baseline system (left side of Fig. 2, HTS-CDBK). With this speech synthesizer one can convert any Hungarian text to human speech, but irregular voice is still not modeled here. Fig. 3 a) shows an example for a synthesized word with the baseline system.
Rule-based irregular voice model
During the investigation of irregular speech, we found several differences compared to regular voice, which can be well represented by rules [C2, J2]. The middle part of Fig. 2 shows the steps of the first model (HTS-CDBK+Irreg-Rule). 1) In irregular phonation the vibration of vocal folds differs from quasi-periodic, and the fundamental frequency (F0) of speech can be extremely low compared to normal speech. This allows using the half of the analyzed F0 in the synthesis phase. 2) During the creation of irregular voice, strong amplitude attenuations appear in the consecutive periods (see Fig. 1). This can be modeled by using amplitude scaling: the consecutive pitch cycles are multiplied by random numbers between {0...1}. 3) The timbre of irregular speech is slightly different from regular voice. We consider it by adding a spectral distortion step to the process. The result of the rule-based irregular voice model can be seen in Fig. 3 b).
Data-driven irregular voice model
Modeling irregular voice can be done in a data-driven manner as well [J2]. The right part of Fig. 2 shows the methods of the second model (HTS-CDBK+Irreg-Data). In the new model, irregular speech sections are automatically chosen from the previously recorded speech database, and re-used in synthesis. 1) Unit selection [13] ensures that the proper irregular excitation section is found that fits in the sentence. 2) The length of the chosen signal section is modified to the target length, and 3) spectral distortion is applied similarly to the rule-based model. Fig. 3 c) shows an example for a synthesized word in the data-driven irregular voice model.
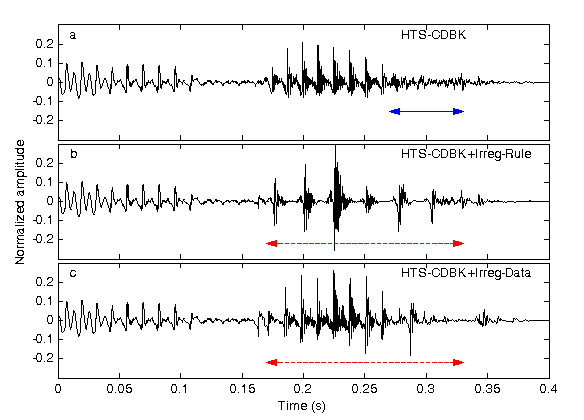
Fig. 3: Synthesized speech waveforms of the word “Mihály” a) baseline b) rule-based irregular voice model c) data-driven irregular voice model.
Results
The difference between the baseline system and the two alternative irregular voice models is clearly visible in Fig. 3. In the section denoted by a horizontal arrow in Fig. 3 a) the baseline system is inappropriate due to the excitation change within the vowel ‘á’. By listening this one could hear a crackling voice which disturbs the intelligibility of synthesized speech. The arrow-denoted section in Fig. 3 b) shows the result of F0 halving in the rule-based system: the individual periods are separated. In this way, the speech reminds of the original rough speech in terms of acoustic and audible cues. The scaled amplitudes are similar to the original irregular sample of Fig. 1. In the output of the data-driven system in Fig. 3 c) only the second part of the vowel ‘á’ shows irregular properties. This is similar to natural speech where only part of a sound is creaky.
Speech databases and samples
For the experiments with the models, two male speakers were chosen from the PPBA database [14]. Both of them use irregular voice frequently, mostly at phrase boundaries. Using 1940 sentences (about 2 hours of recordings) from the speakers HMM-based voices were created with all three methods (baseline, rule-based and data-driven irregular model). Next, 130 sentences were synthesized from text to speech, and 10 samples were chosen for later analysis. Each sample was a word containing irregular part(s). Several examples for the samples can be heard by clicking on the links of Table 1.
Table 1: Synthesized speech samples from two speakers of the PPBA database. Full version for listening.
HTS-CDBK (regular voice) | HTS-CDBK+Irreg-Rule (rule-based irregular) | HTS-CDBK+Irreg-Data (data-driven irregular) |
Listening tests
The synthesized samples were evaluated extensively: we created internet-based listening tests [C2], [J2]. In the 1st test the rule-based irregular voice model was compared to the baseline, while in the 2nd test the data-driven irregular model was evaluated. After listening each sample pairs, listeners were asked to answer two questions regarding the pleasantness and the similarity to the original speaker.
The 1st test was evaluated by 11 subjects (speech technology experts) in 9 minutes on average, while in the 2nd test 16 listeners (university students) participated. The answers of listeners were analyzed with paired samples t-tests and ANOVA analysis. According to the results of the 1st experiment, the subjects perceived the new, HTS-CDBK+Irreg-Rule samples significantly (p<0.0005) more natural than the baseline system. The utterances of the new model were evaluated as being significantly (p<0.0005) more similar to the original speaker. The 2nd test showed similar preferences with regard to the HTS-CDBK+Irreg-Data system against the baseline.
The conclusion of the subjective listening tests is that the subjects clearly accepted the synthesized samples generated by the new models, and thus the methods can be used in future machine systems.
Acoustic analysis
The synthesized speech samples were compared to an acoustic analysis as well, the details of which can be read in papers [C2] and [J2]. According to the results of the acoustic experiments, the speech samples synthesized by the irregular voice models are close to the original, natural irregular speech samples in terms of several relevant acoustic cues.
Expected impact and further research
Irregular voice is frequently used in everyday speech for expressing emotions or marking sentence boundaries [5], [12]. The two alternative irregular voice models that were developed here made synthesized speech sound more natural. A system like this allows creation of personalized systems, speaking in the voice of a given speaker. This can be particularly useful in mobile applications for helping the communication of people with speech disorders. Besides, the models can improve the expressive, emotional speech synthesis.
The impact and actuality of the current research is shown by two main facts. Several foreign research groups (Trinity College Dublin, University of Mons, Aalto University) also deal with the investigation and synthesis of irregular voice. At the latest and largest conferences of speech technology (Interspeech 2012, Interspeeh 2013, ICASSP 2013) numerous papers dealt with these topics, e.g. [10], [11], [15].
Publications, references, links
Publications:
[J1] Tamás Gábor Csapó, Géza Németh, Statistical parametric speech synthesis with a novel codebook-based excitation model. Intelligent Decision Technologies, accepted, 2013.
[J2] Tamás Gábor Csapó, Géza Németh, Modeling irregular voice in statistical parametric speech synthesis with residual codebook based excitation. IEEE Journal on Selected Topics in Signal Processing, submitted, 2013.
[C1] Tamás Gábor Csapó, Géza Németh, A novel codebook-based excitation model for use in speech synthesis. in IEEE CogInfoCom 2012, (Kosice, Slovakia), pp. 661–665, 2012.
[C2] Tamás Gábor Csapó, Géza Németh, A novel irregular voice model for HMM-based speech synthesis. in Proc. ISCA 8th Speech Synthesis Worksop (SSW8), submitted, 2013.
Full publication list
Links:
Statistical parametric speech synthesis
HMM-based speech synthesis system (HTS), open source program
1000 voices in HMM-based speech synthesis
Voice quality samples (English regular, English irregular, English breathy)
Synthesized irregular voice samples in the current application
Celebrities are also using irregular voice
Weather forecast program for Windows 8 with speech synthesis
References:
[1] H. Zen, K. Tokuda, and A. W. Black, Statistical parametric speech synthesis. Speech Communication, vol. 51, pp. 1039–1064, Nov. 2009.
[2] B. Tóth and G. Németh, Improvements of Hungarian Hidden Markov Model-based Text-to-Speech Synthesis. Acta Cybernetica, vol. 19, no. 4, pp. 715–731, 2010.
[3] D. H. Klatt and L. C. Klatt, Analysis, synthesis, and perception of voice quality variations among female and male talkers. The Journal of the Acoustical Society of America, vol. 87, pp. 820–857, Feb. 1990.
[4] M. Blomgren, Y. Chen, M. L. Ng, and H. R. Gilbert, Acoustic, aerodynamic, physiologic, and perceptual properties of modal and vocal fry registers. The Journal of the Acoustical Society of America, vol. 103, pp. 2649–2658, May 1998.
[5] T. Bőhm, Z. Both, and G. Németh, Automatic Classification of Regular vs. Irregular Phonation Types. in NOLISP, (Vic, Spain), pp. 43–50, 2009.
[6] J. Kane, T. Drugman, and C. Gobl, Improved automatic detection of creak. Computer Speech & Language, vol. 27, pp. 1028–1047, June 2013.
[7] A. McCree and T. Barnwell, A mixed excitation LPC vocoder model for low bit rate speech coding. IEEE Transactions on Speech and Audio Processing, vol. 3, pp. 242–250, July 1995.
[8] T. Bőhm, N. Audibert, S. Shattuck-Hufnagel, G. Németh, and V. Aubergé, Transforming modal voice into irregular voice by amplitude scaling of individual glottal cycles. in Acoustics’08, (Paris, France), pp. 6141–6146, 2008.
[9] H. Silén, E. Helander, J. Nurminen, and M. Gabbouj, Parameterization of vocal fry in HMM-based speech synthesis. in Proc. Interspeech, (Brighton, UK), pp. 1775–1778, 2009.
[10] T. Drugman, J. Kane, and C. Gobl, Modeling the Creaky Excitation for Parametric Speech Synthesis. in Proc. Interspeech, (Portland, Oregon, USA), pp. 1424–1427, 2012.
[11] T. Raitio, J. Kane, T. Drugman, and C. Gobl, HMM-based synthesis of creaky voice. in Proc. Interspeech, pp. 2316-2320., 2013.
[12] T. Drugman, G. Wilfart, and T. Dutoit, A deterministic plus stochastic model of the residual signal for improved parametric speech synthesis. in Proc. Interspeech, (Brighton, UK), pp. 1779–1782, 2009.
[13] A. Hunt and A. Black, Unit selection in a concatenative speech synthesis system using a large speech database. in Proc. ICASSP, vol. 1, (Atlanta, Georgia, USA), pp. 373–376, 1996.
[14] G. Olaszy, Precíziós, párhuzamos magyar beszédadatbázis fejlesztése és szolgáltatásai [Development and services of a Hungarian precisely labeled and segmented, parallel speech database] (in Hungarian). Beszédkutatás 2013 [Speech Research 2013], 2013.
[15] T. Drugman, J. Kane, T. Raitio, and C. Gobl, Prediction of Creaky Voice from Contextual Factors. in Proc. ICASSP, (Vancouver, Canada), 2013.