|
|
BMe Research Grant |
|

Reichardt Richárd
BMe Research Grant - 2021
![]()
Doctoral School of Psychology (Cognitive Science)
BME TTK, Department of Cognitive Science
Supervisor: Dr. Simor Péter Dániel
Memorable differences: predictive coding in human memory
Introducing the research area
In recent years, predictive coding has become one of the most influential ideas in neuroscience 1,2. The main idea is that the brain constantly tries to predict incoming information, thus making information processing more efficient. Several findings from cognitive neuroscience support that predictive coding influences memory processes 3. The studies presented here aim to assess a hypothesis derived from predictive coding, using visual stimuli that can easily be expressed numerically. This approach may allow the discovery of the subtle rules of memory processes that are fundamental to understand the brain and may revolutionize the transfer of knowledge.
Brief introduction of the research place
The Budapest Laboratory of Sleep and Cognition, founded by Dr. Simor Péter Dániel, belongs to the Institute of Psychology of ELTE. The main research topics at the lab include the neurophysiology of sleep, sleep disorders and associated daytime symptoms, and the cognitive neuroscience of the relationship between sleep and memory.
History and context of the research
Predictive coding is a general information processing strategy that is supposed to be a basic motif of brain function 4. The constant prediction of incoming information saves energy for the brain as only inaccurately predicted information needs further processing. The degree of inaccuracy is called the prediction error. One pivotal idea of predictive coding is that the brain has to build an inner model of the outside world which is accurate enough that prediction errors are as infrequent and small as possible.
|
|
|
Figure 1: The main idea of predictive coding is that incoming information is compared to predictions in the brain. Inaccurate predictions result in prediction errors, which initiate the updating of the inner model that is the source of predictions. |
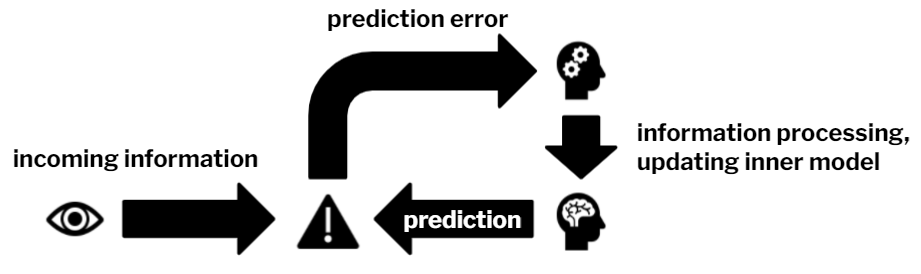
Predictive systems minimize prediction errors by treating them as learning signals: prediction errors indicate the necessity of learning, the need to update the inner model of the world. This internal model actually corresponds to the memory, our knowledge of the world and its workings. A basic assumption of memory models based on predictive coding is that humans learn when they stumble upon unexpected information. This conclusion seems to be supported by several recent results 5,6. However, even though the theory itself proposes that prediction error is a continuous variable, current methods in cognitive neuroscience handle the variability in the prediction status of events as categorical (e. g. predicted vs. unpredicted stimuli) 7,8. This limitation should be overcome in the field so that models of memory function based on predictive coding could be assessed in more depth.
The research goals, open questions
The goal of our research was to go beyond current methods in cognitive neuroscience and create a technique that can be used to assess the subtler rules of memory formation. We developed a technique to generate a stimulus pool in which visual stimuli can easily be expressed in numbers. In this way, by calculating the differences between stimuli, a continuous variable can be obtained, which can represent the prediction error in a suitable experimental task.
Thanks to modern methods in information technology, the numerical representation of pictures is not a challenge. However, as our goal here is to study human memory, we have to make sure that this numerical representation is built up from chunks that are understandable to a human observer too 9. If we manage to create a stimulus pool that meets these requirements, it can be expected that we can replicate classical phenomena in memory research using these stimuli. Of the stimulus pool, humans usually remember those stimuli better that are more different from the others 10. This classic finding can be easily explained in the framework of predictive coding: different stimuli elicit greater prediction errors than similar ones, because they are more difficult to predict. The current studies thus seek to answer the question of whether it is possible to use visual stimuli that can be expressed numerically in the studies of memory processes. To address this issue, we developed an algorithm that generates a stimulus pool for use in a simple experimental task to see if these stimuli can be meaningfully processed by the memory system of humans.
Methods
The first step of the research project was to work out the appearance of stimuli. The most important considerations were that the stimuli have to be numerically expressible and that the numerical code has to represent elements comprehensible for a human observer. The fact that stimuli are numerically expressible ensures that the differences between stimuli can be calculated, and thus the variable used to estimate the prediction error can be a continuous variable. Based on these considerations we used pictures made up of simple, colored shapes. Every picture contained five colored shapes that could occupy nine possible locations. We used three vectors to describe the pictures numerically, the first represented the arrangement of the shapes in the possible locations, the second represented the color of the shapes and the third represented the type of the shape. The difference between the two pictures was calculated by summing the number of differences between the corresponding vectors representing the pictures.
|
|
|
Figure 2: A typical stimulus from the study and the vectors describing it are visible on the left. The difference categories used in the experimental task with example stimuli are visible on the right. |
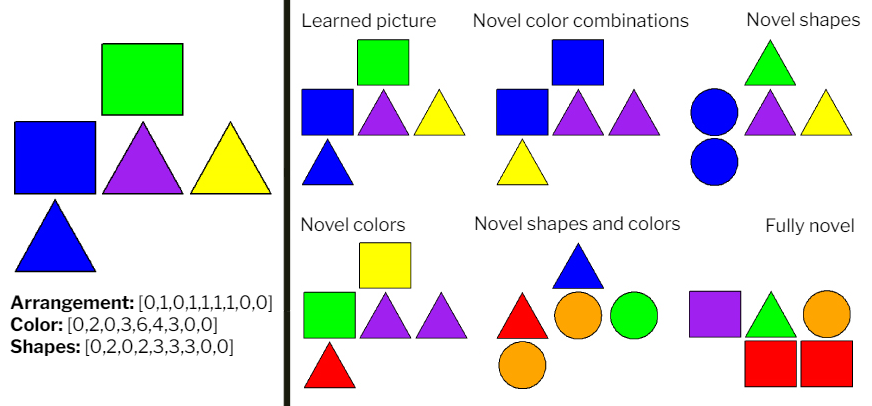
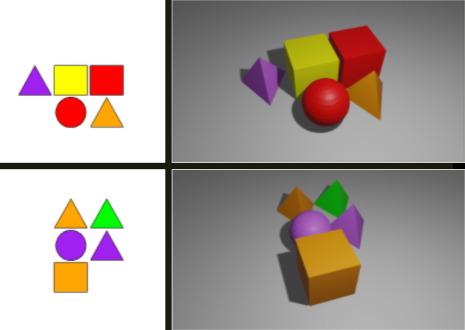
We designed the algorithm generating the stimulus pool mindful of the experimental task. The essence of the experimental task was that participants had to memorize a few repeatedly presented pictures which differed from each other substantially, then we presented new stimuli that differed to varying degrees from the learned stimuli, and finally we assessed their recognition memory for these new stimuli. In this way, the prediction error generated by each novel picture supposedly depended on the degree of difference from the most similar learned picture. The algorithm generated five different categories of novel stimuli by changing the vectors describing the stimuli to be learned (for example, in one category, the vector representing the shapes was changed [novel shapes] while the vector representing the colors was kept constant and in another one, the opposite was done [novel colors]). In the first experiment we used the graphic library of the R language (grDevices) to produce the pictures. We then assessed how the performance of the participants changes when used more complex, three-dimensional pictures in the task. In the second experiment, we generated three-dimensional pictures based on the rules described before, using Blender to render the stimuli.
|
|
|
Figure 3: The stimuli used in the first experiment are visible on the left, the stimuli used in the second experiment are visible on the right. |
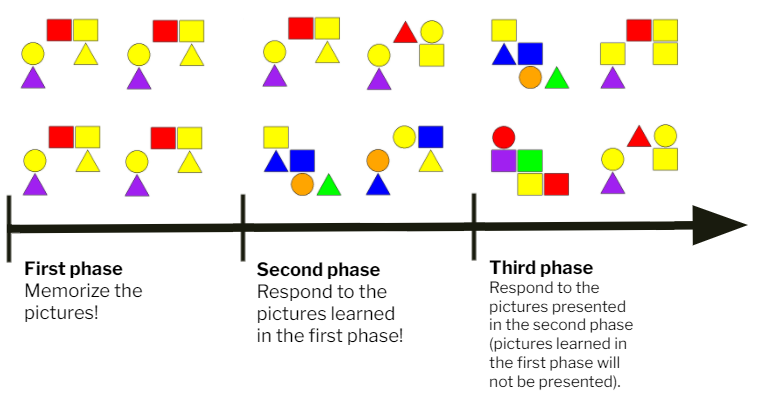
The participants looked at five pictures presented repeatedly in the first phase of the experimental task. They were instructed to memorize these pictures. In the next phase, participants were presented both with the learned pictures and several novel pictures. Their task was to signal with a fast button press if the currently presented picture is one of the learned pictures or a novel one. Finally, in the last phase participants could see the novel pictures from the second phase and distractor pictures which were similar to the novel ones. Participants had to signal whether or not they had seen the picture (distractors were not presented previously, thus responses to these pictures could be used to calculate reliable recognition responses – the corrected recognition index). Thus, during the task, the participants memorized five pictures, then they saw novel pictures which varied in the degree of difference from the learned pictures, and finally we assessed their recognition memory for these novel stimuli.
|
|
|
Figure 4: The outline of the experimental task. |
Results
Due to the coronavirus pandemic, we collected data online. The first experiment was completed by 95 participants (78 females, mean age: 24.8 ± 6.9), the second experiment with the three-dimensional stimuli was completed by 62 participants (48 females, mean age: 22.0 ± 2.7). In the second phase, the participants answered correctly in more than 75% of the trials (Experiment 1: 75.6%; Experiment 2: 78.0%). When using natural scenes as stimuli in similar tasks, performance is usually above 90% 11. This result shows that participants had difficulties in memorizing and differentiating between these stimuli, however, their performance is high enough to ensure that the responses from the third phase of the experiment are also suitable for analysis.
The critical data to assess our hypothesis was provided by the responses obtained in the third phase of the task. According to our hypothesis, the more different the new stimulus presented in the second phase is from the stimulus most similar to the first phase, the more likely it is to be recognized correctly in the third phase. The results of the first experiment confirmed our hypothesis. First, we used analysis of variance (ANOVA) to assess the participants’ corrected recognition of novel pictures by different categories. We calculate the corrected recognition score by subtracting the number of incorrect responses to the distractor pictures from the number of correct responses to the previously presented pictures for every picture category. The factor representing the difference categories showed a statistically significant main effect. In addition, the categories and the corrected recognition score showed a linear relationship: the corrected recognition index was the highest for the category of the most different pictures and it decreased gradually in the other categories. We confirmed our findings with logistic mixed regression. This method enables the assessment of experimental data on the level of single trials; thus, we analyse not merely the mean scores describing the overall performance of a participant, but all their responses 12. In this analysis, we used the difference indicator calculated by comparing the vectors describing a novel picture and the learned picture most similar to it. The model showed that the participants could not reliably recognize pictures similar to the stimuli presented in the first phase, however, they succeeded with more different pictures. Thus, these results resonate with the presupposition of the experiment: the more different a stimulus is from other stimuli presented in a task, the more likely it is to be recognized later.
|
|
|
Figure 5: According to the logistic mixed regression model, the stimuli with a higher difference index were more accurately recognized in the third phase of the experimental task. |
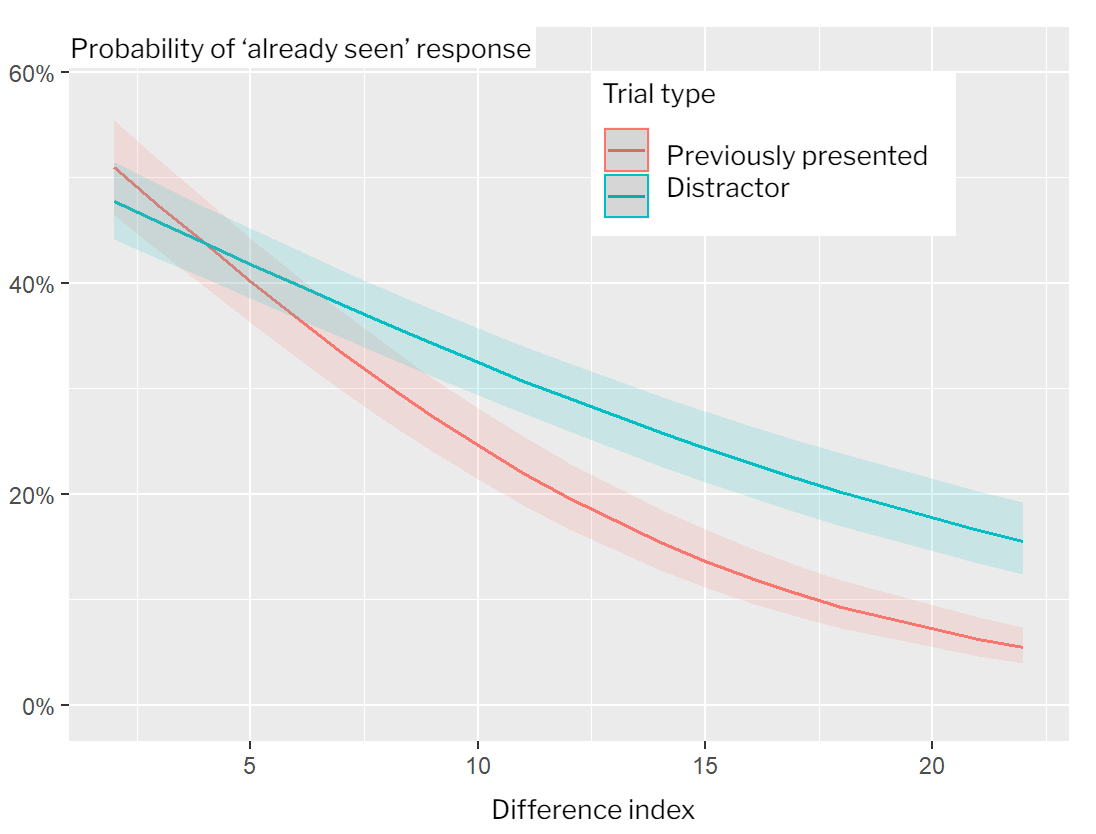
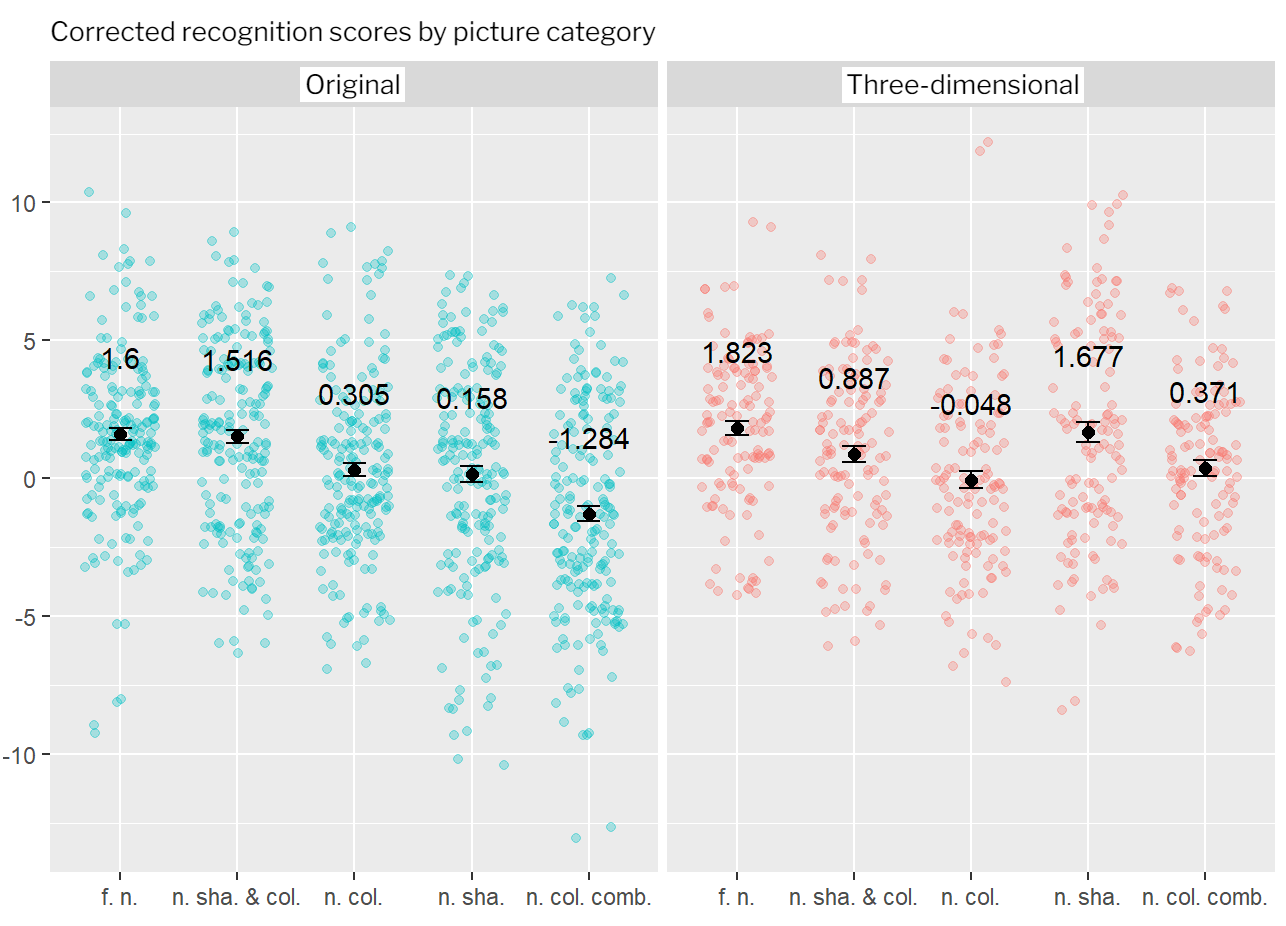
The results described earlier could be observed in the data of the second experiment, with the exception that the shapes vector had a greater effect on the corrected recognition score. Comparison of the recognition scores of the two experiments in a single ANOVA model showed that using the three-dimensional stimulus pool did not result in a significantly better memory performance, but participants in the second experiment remembered the pictures in the novel shapes category better than participants in the first experiment (which also means that we did not observe a linear trend in the difference categories in this experiment).
|
|
|
Figure 6: Means of the corrected recognition scores by novel picture categories observed in the first and the second experiment (colored dots represent the means of individual participants). In the case of the three-dimensional stimulus pool, the category created by changing the shapes vector resulted in significantly higher corrected recognition score, however, the overall recognition performance did not differ in the two experiments (Abbreviations: f.n. - fully novel; n. sha. & col. - novel shapes and colors; n. col. - novel colors; n. sha. - novel shapes; n. col. comb. - novel color combinations). |
Expected impact and further research
These experiments show that numerically expressible visual stimuli and the differences between them are comprehensible and memorizable to the human mind. This approach enables the in-depth assessment of memory models based on predictive coding and the mathematical relationship between the expectedness and the memorability of a stimulus. The next step in the research project is to increase the memorability of the stimulus pool. Even though we failed to achieve this by using three-dimensional stimuli, there are several other methods to be evaluated. Increasing the memorability of these numerically expressible stimuli could enable the study of memory consolidation and memory evolution, which take place mostly during sleep.
Publications, references, links
List of corresponding own publications.
R. Reichardt, B. Polner, and P. Simor, “Novelty Manipulations, Memory Performance, and Predictive Coding: The Role of Unexpectedness,” Front. Hum. Neurosci., vol. 14, no. April, pp. 1–11, 2020.
Table of links.
Popular science articles on memory and learning (in Hungarian):
https://agykutatasegyszeruen.hu/2021/04/15/az-emlekek-evolucioja/
https://agykutatasegyszeruen.hu/2019/04/09/az-alvas-emlekezeti-funkcioja/
https://agykutatasegyszeruen.hu/2018/10/05/hogyan-dolgozza-fel-az-uj-informaciokat-az-agy/
https://tudas.hu/az-agykutatok-magara-a-kivancsisagra-is-kivancsiak/
Popular science articles on predictive coding (in Hungarian):
https://agykutatasegyszeruen.hu/2020/10/29/a-felderites-kiaknazas-dilemma/
https://agykutatasegyszeruen.hu/2020/03/19/az-ovtekerveny-mukodese/
List of references.
1. Friston, K. The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138 (2010).
2. Friston, K. Does predictive coding have a future? Nat. Neurosci. 21, 1019–1021 (2018).
3. van Kesteren, M. T. R., Ruiter, D. J., Fernández, G. & Henson, R. N. How schema and novelty augment memory formation. Trends Neurosci. 35, 211–219 (2012).
4. Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36, 181–204 (2013).
5. Quent, J. A., Henson, R. N. & Greve, A. A predictive account of how novelty influences declarative memory. Neurobiol. Learn. Mem. 179, 107382 (2021).
6. Frank, D. & Kafkas, A. Expectation-driven novelty effects in episodic memory. Neurobiol. Learn. Mem. 183, 107466 (2021).
7. Schomaker, J. & Meeter, M. Short- and long-lasting consequences of novelty, deviance and surprise on brain and cognition. Neurosci. Biobehav. Rev. 55, 268–279 (2015).
8. Barto, A., Mirolli, M. & Baldassarre, G. Novelty or Surprise? Front. Psychol. 4, (2013).
9. Rust, N. C. & Mehrpour, V. Understanding Image Memorability. Trends Cogn. Sci. 24, 557–568 (2020).
10. von Restorff, H. Über die Wirkung von Bereichsbildungen im Spurenfeld. Psychol. Forsch. 18, 299–342 (1933).
11. Wittmann, B. C., Bunzeck, N., Dolan, R. J. & Düzel, E. Anticipation of novelty recruits reward system and hippocampus while promoting recollection. NeuroImage 38, 194–202 (2007).
12. Lo, S. & Andrews, S. To transform or not to transform: using generalized linear mixed models to analyse reaction time data. Front. Psychol. 6, (2015).