|
|
BMe Kutatói pályázat |
|

Reichardt Richárd
BMe kutatói pályázat - 2021
![]()
Pszichológia Doktori Iskola (Kognitív Tudomány)
BME TTK, Kognitív Tudományi Tanszék
Témavezető: Dr. Simor Péter Dániel
Emlékezetes eltérések: prediktív kódolás az emberi emlékezetben
A kutatási téma néhány soros bemutatása
Az utóbbi években a prediktív kódolás az idegtudomány egyik legnagyobb hatású elképzelésévé nőtte ki magát 1,2. A központi gondolata az, hogy az agy folyamatosan igyekszik bejósolni, prediktálni a bejövő információt, ezzel hatékonyabbá téve az információ feldolgozását. Egyre több eredmény támasztja alá, hogy a prediktív kódolás az emlékezeti folyamatokban is tetten érhető 3. A most bemutatott kutatás célja, hogy a prediktív kódolásból következő szabályszerűségeket az emlékezeti teljesítményben pontosan számszerűsíthető, vizuális ingerek segítségével vizsgálja. Ez a megközelítés lehetővé teheti az emlékezeti folyamatok finomabb szabályszerűségeinek feltárását, ami alapvető jelentőségű az agyműködés megértése szempontjából, és a tudásátadás korszerűsítésében is központi fontosságú lehet.
A kutatóhely rövid bemutatása
A Budapesti Alvás és Kogníció Laboratóriumot (Budapest Laboratory of Sleep and Cognition) Dr. Simor Péter Dániel alapította, jelenleg az ELTE Pszichológia Intézetéhez tartozik. A laborban hangsúlyos az alvás élettanának kutatása, a különféle alvászavarok, illetve az ezekhez köthető nappali tünetek tanulmányozása, illetve az alvás alatti emlékezeti folyamatok kognitív idegtudományi vizsgálata.
A kutatás történetének, tágabb kontextusának bemutatása
A prediktív kódolás egy általános információfeldolgozási stratégia, amit a modern idegtudomány az agyműködés egyik alapmotívumának tart 4. A bejövő információ folyamatos bejóslása azt eredményezi, hogy csak a pontatlanul megjósolt részletek esetében van szükség energiaigényes információfeldolgozásra. A pontatlanság mértékét predikciós hibának nevezzük. Az elmélet másik sarkalatos pontja, hogy a jósláshoz olyan belső modellre van szüksége az agynak, amely elég jól képezi le a külvilágot ahhoz, hogy a predikciós hibák mértéke a lehető legkisebb legyen.
|
|
|
1. ábra: A prediktív kódolás lényege, hogy a bejövő információt az elvárásokhoz hasonlítja az agy. A pontatlan elvárások nyomán keletkező predikciós hibák frissítik a belső modellt, ami az elvárásokat generálja. |
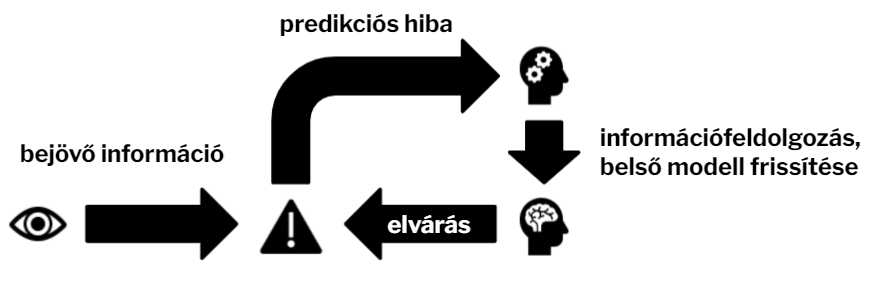
A prediktív rendszerek úgy érik el a predikciós hibák minimalizálását, hogy tanulnak azokból: a predikciós hiba a tanulás szükségességét jelzi, a belső modell frissítéséért felel. Ez a belső modell tulajdonképpen megfeleltethető a klasszikus értelemben vett emlékezetnek. A prediktív kódoláson alapuló emlékezeti modellek legalapvetőbb feltevése tehát az, hogy az ember akkor tanul, ha váratlan információba ütközik. Ezt a következtetést számos friss kutatási eredmény látszik alátámasztani 5,6. Fontos szempont azonban, hogy míg az elmélet maga folytonos változóként kezeli a predikciós hibát, addig a kognitív idegtudomány gyakorlatában a váratlanság mértéke általában kategorikus változóként jelenik meg (pl. várt vagy váratlan ingerek) 7,8. Ezen a limitáción fontos lenne túllépnie a területnek ahhoz, hogy a prediktív kódolásból következő feltevéseket részleteiben is el lehessen bírálni, és kiderülhessen, hogy megfelelő modellje-e az emlékezeti rendszerek működésének valamelyik prediktív kódoláson alapuló memóriamodell.
A kutatás célja, a megválaszolandó kérdések.
A kutatás célja, hogy az eddig alkalmazott kísérleti megközelítéseken túllépve olyan módszert hozzon létre, amely alkalmas az emlékezeti folyamatok szabályszerűségeinek pontosabb feltárására. A kutatás során olyan eljárást fejlesztettünk, mellyel könnyen számszerűsíthető vizuális ingerekből álló ingeranyag hozható létre. Az ingerek közti különbségek így akár folytonos változóként is kifejezhetők, ez pedig a megfelelő kísérleti elrendezésben megfeleltethető a predikciós hiba mértékét kifejező folytonos változónak.
A modern számítógépes módszereknek köszönhetően a vizuális ingerek számszerűsítése nem különösebb kihívás. Az emlékezet vizsgálata szempontjából azonban központi jelentőségű, hogy a számokkal kifejezett egységeknek a megfigyelő ember számára is értelmezhetőnek kell lenniük 9. Ha sikerül ezen szempontoknak megfelelő ingeranyagot létrehozni, akkor elvárható, hogy annak használatával replikálható az emlékezet működésének egy klasszikus jelensége. Egy ingeranyagból az emberek általában azokra az ingerekre emlékeznek jobban, amelyek eltérnek a többitől 10. Ez jól magyarázható a prediktív kódolás elméleti keretében: az eltérő ingerek nagyobb predikciós hibát váltanak ki, mint a hasonlóak, mert kevésbé felelnek meg az elvárásoknak. A jelen kutatás által megválaszolni kívánt kérdés tehát az, hogy lehetséges-e könnyen számszerűsíthető ingereket használni az emlékezetet tesztelő kísérleti elrendezésekben. A kérdés eldöntésére kidolgoztunk egy algoritmust, ami kész ingeranyagot generál, az ingeranyagot pedig egy egyszerű kísérleti elrendezésben használtuk fel, hogy kiderüljön, megbirkózik-e a képekkel az emberi emlékezet.
Módszerek
A kísérlet első lépése az ingerek megjelenésének kidolgozása volt. A fő szempontok, hogy az ingerek egyszerűen számszerűsíthetők legyenek, és a kód a megfigyelő számára is értelmes egységeket takarjon. Az ingerek számszerűsíthetősége biztosítja, hogy az ingerek közti különbség is kiszámítható legyen, ez pedig alapvető feltétele annak, hogy a predikciós hiba mértékét folytonos változóval becsülhessük. Ezen megfontolások alapján egyszerű, színes alakzatokból álló képeket használtunk. Minden kép öt színes alakzatot tartalmazott, melyek kilenc lehetséges pozíciót töltöttek be. Az ábrákat három vektor segítségével írtuk le, melyek közül az első azt mutatta, hogy a kilenc lehetséges pozícióból melyiken helyezkedik el alakzat, a második, hogy az adott alakzat milyen színű, a harmadik pedig, hogy pontosan milyen alakzatról van szó. Az ingerek közti különbség az adott ingerpár vektorai között található eltérések összege.
|
|
|
2. ábra: Balra egy tipikus ábra a kísérletből, és az ábrát definiáló vektorok. Jobbra a kísérletben használt különbségi kategóriák és egy-egy példa. |
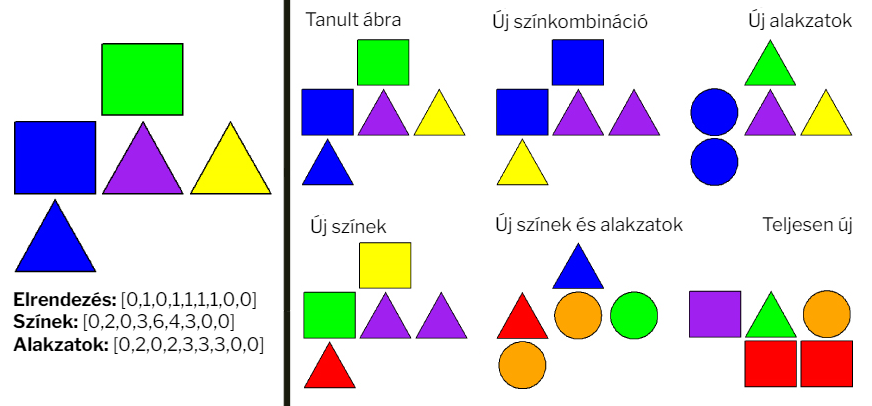
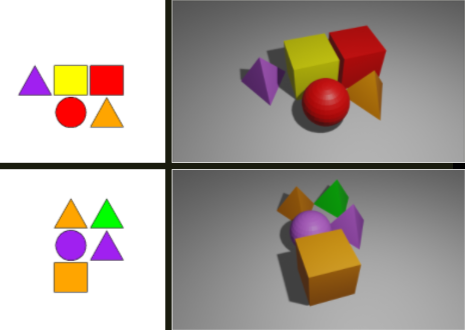
Az ingeranyagot létrehozó algoritmust már a kísérleti elrendezésnek megfelelően alakítottuk ki. A kísérleti elrendezés lényege az volt, hogy néhány, egymástól jelentősen eltérő ingert többszöri bemutatással alaposan megjegyeztettünk a résztvevőkkel, aztán ezektől különböző mértékben eltérő új ingereket is bemutattunk nekik és végül azt vizsgáltuk, hogy ezeket az új ingereket képesek-e felismerni a kísérlet egy későbbi szakaszában. A predikciós hiba mértékét így feltevésünk szerint az határozta meg, hogy mennyire tért el egy új inger a hozzá leginkább hasonlító, tanult ingertől. Az algoritmus öt különböző kategóriájú új képet hozott létre úgy, hogy a tanulásra szánt képek különböző dimenzióit variálta (az egyik csoportban például az alakzatokat cserélte le, a színeket megtartotta [új alakzatok], míg egy másikban épp fordítva [új színek]). A képek előállításához az első kísérletben az R nyelv grafikus könyvtárát (grDevices) használtuk. Ezután megvizsgáltuk, hogyan alakul a résztvevők teljesítménye abban az esetben, ha az ingeranyagot térhatású képekből állítjuk össze. A második kísérletben az ingyenesen hozzáférhető Blender nevű szoftver segítségével generáltunk térhatású képeket az eredeti szabályoknak megfelelően.
|
|
|
3. ábra: Balra az első kísérletben használt képek, jobbra a térhatású ábrák a második kísérletből. |
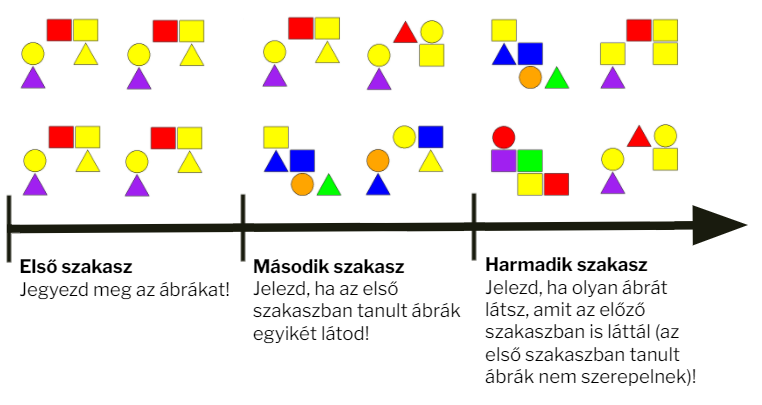
A kísérleti feladat során a résztvevők először öt képet néztek meg, több ismétléssel. Azt az utasítást kapták, hogy jegyezzék meg ezeket a képeket. A következő szakaszban a résztvevők az eredeti képek mellett új képeket is láttak. A feladatuk ezúttal az volt, hogy egy gyors gombnyomással jelezzék, hogy az éppen bemutatott kép egyike-e az eredetileg tanult képeknek, vagy sem. Ezután következett az utolsó szakasz, amelyben a résztvevők a korábban bemutatott új képek mellett ezekhez hasonló, de korábban még nem látott, elterelő képeket is láttak. A résztvevőknek jelezniük kellett, hogy az éppen bemutatott képet látták-e a második szakaszban (az elterelő képeket nem láthatták, így az ezekre adott válaszokból kiszámítható volt a megbízható felismerési válaszok száma – a korrigált felismerési mutató). A feladat során a résztvevők tehát alaposan megjegyeztek néhány ábrát, majd ezektől különböző mértékben eltérő ábrákat láttak a második szakaszban, végül pedig leteszteltük, hogy mennyire emlékeznek ezekre az eltérő képekre.
|
|
|
4. ábra: A kísérlet menetének vázlata. |
Eddigi eredmények
A kísérleti feladatot a koronavírus okozta helyzetből fakadóan online vettük fel a résztvevőkkel. Az első kísérletet 95 személy teljesítette (78 nő, átlagéletkor: 24,8 ± 6,9), a második kísérletet a térhatású ábrákkal 62 résztvevő végezte el (48 nő, átlagéletkor: 22,0 ± 2,7). A második szakaszban mindkét kísérlet során az esetek több mint háromnegyedében adtak helyes válaszokat a résztvevők (1. kísérlet: 75,6%; 2. kísérlet: 78,0%). Hasonló elrendezésekben, amelyek természetes képeket használnak ingeranyagként, a teljesítmény általában 90% fölött van11. Ez az eredmény azt tükrözi, hogy az egyszerű alakzatokat ábrázoló képek megjegyzése és elkülönítése nem volt könnyű feladat a kísérleti résztvevőknek, viszont ahhoz elég jól teljesítettek, hogy harmadik szakaszban adott válaszok is értékelhetőek legyenek.
A hipotézis szempontjából a kritikus információt a harmadik szakasz adatai szolgáltatták. A feltevés az volt, hogy minél jobban eltér egy második szakaszban bemutatott kép a hozzá leginkább hasonló tanult képtől, annál nagyobb az esélye, hogy helyesen ismerik fel azt a résztvevők. Az első kísérlet eredményei igazolták elvárásunkat. Először varianciaanalízissel (ANOVA) vizsgáltuk a résztvevők által produkált átlagos korrigált felismerést a különbözőségi kategóriák szerint. A korrigált felismerést úgy számoljuk ki, hogy a korábban bemutatott képekre adott helyes válaszokból kivonjuk az elterelő képekre adott helytelen válaszokat. A különbözőségi kategóriákat reprezentáló csoportosító változó statisztikailag szignifikáns hatást mutatott. A csoportok és a korrigált felismerés között ráadásul lineáris összefüggés volt: a leginkább eltérő képek csoportjára volt a legmagasabb a korrigált felismerési mutató, és ez fokozatosan csökkent a kevésbé különböző képek csoportjainál. Az eredményeket logisztikus regressziós kevert modellel erősítettük meg. Ez a módszer lehetővé teszi, hogy az egyes próbák szintjén elemezzük ki az adatokat, tehát nem csupán a résztvevők teljesítményét jellemző átlagokat vizsgáljuk, hanem gyakorlatilag minden egyes válaszukat12. Ehhez az elemzéshez már nem az új képek kategóriáit, hanem az adott kép és a hozzá leghasonlóbb tanult kép összehasonlításával kapott különbségi mutatót használtuk. Az eredmények szerint a kisebb különbségi mutatóval bíró képek esetén a résztvevőknek nem sikerült jól elkülöníteni a korábban már látott képeket az elterelő képektől, míg a nagyobb különbségek esetén már sikerrel jártak. Ezek az eredmények tehát összhangban vannak a vizsgálat alapjául szolgáló feltevéssel: minél jobban eltér egy inger a többi bemutatott ingertől, annál nagyobb eséllyel jegyzik azt meg a kísérleti résztvevők.
|
|
|
5. ábra: A logisztikus regressziós kevert modell szerint a nagyobb különbözőségi mutatóval jellemezhető képek esetén pontosabbak voltak a felismerési válaszok az első kísérlet harmadik szakaszában. |

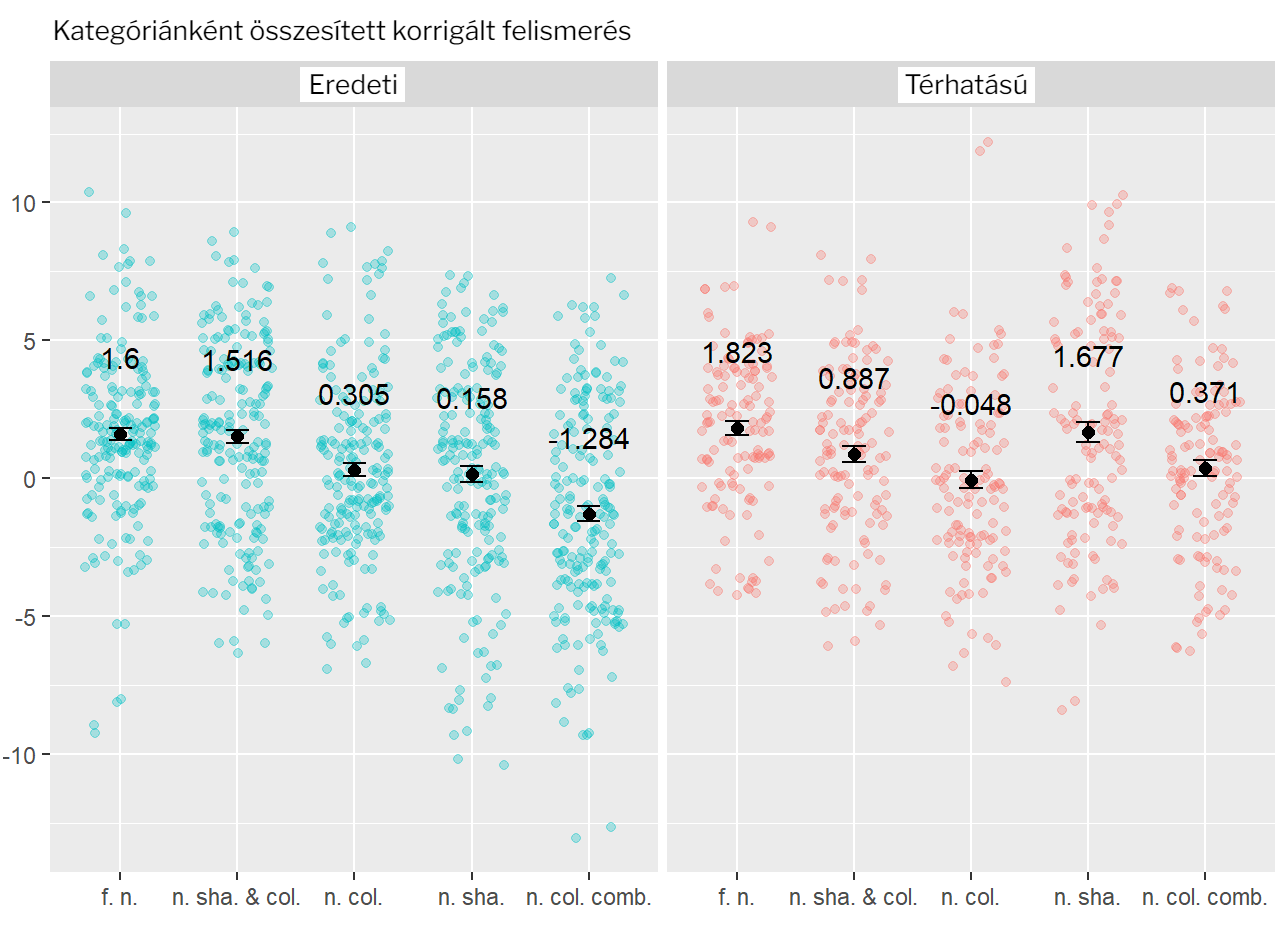
A fent említett eredmények a térhatású ábrákkal végzett második kísérletben is megjelentek, azzal a különbséggel, hogy az alakzatok vektorának jóval nagyobb hatása volt a képek felismerésére. A két vizsgálat összevetésére készített ANOVA elemzés szerint összességében ugyan nem produkáltak számottevően jobb teljesítményt a résztvevők a második kísérletben, azokra a képekre azonban jelentősen jobban emlékeztek, amelyek az alakzatokban tértek el az eredeti képekhez képest (így az első kísérletben látott lineáris trend sem jelent meg).
|
|
|
6. ábra: Az első és a második kísérletben tapasztalt kategóriánként összesített korrigált felismerési mutatók átlaga (a színes pöttyök az egyes résztvevők átlagait mutatják). A térhatású ábrák esetében az alakzatok variálásával létrehozott képek szignifikánsan jobb felismerést eredményeztek, összességében azonban nem tért el jelentősen a felismerési teljesítmény a két vizsgálatban (A rövidítések jelentése: f.n. – teljesen új; n. sha. & col. – új színek és alakzatok; n. col. – új színek; n. sha. – új alakzatok; n. col. comb. – új színkombinációk). |
Várható impakt, további kutatás
A kísérletek alátámasztják, hogy a számokkal könnyen kifejezhető ingerek és a köztük lévő különbségek az emberi elme számára is felfoghatók és megjegyezhetők. Ez a megközelítés lehetővé teszi, hogy a prediktív kódoláson alapuló emlékezeti modellek által felvázolt matematikai összefüggések az ingerek váratlansága és azok emlékezetessége között részleteikben is elbírálhatók legyenek. A kutatási projekt következő lépése a képek emlékezetességének általános javítása. Ezt ugyan nem sikerült elérni a térhatású ábrákkal, de számos más lehetőség vár még tesztelésre. A képek emlékezetességének fokozása lehetőséget adna például az emléknyomok hosszú távú átalakulásainak vizsgálatára is, amely nagyobb részt az alvás alatt zajlik.
Saját publikációk, hivatkozások, linkgyűjtemény
Kapcsolódó saját publikációk listája.
R. Reichardt, B. Polner, and P. Simor, „Novelty Manipulations, Memory Performance, and Predictive Coding: the Role of Unexpectedness,” Front. Hum. Neurosci., vol. 14, no. April, pp. 1–11, 2020.
Linkgyűjtemény.
Néhány cikk az emlékezettel és a tanulással kapcsolatban
https://agykutatasegyszeruen.hu/2021/04/15/az-emlekek-evolucioja/
https://agykutatasegyszeruen.hu/2019/04/09/az-alvas-emlekezeti-funkcioja/
https://agykutatasegyszeruen.hu/2018/10/05/hogyan-dolgozza-fel-az-uj-informaciokat-az-agy/
https://tudas.hu/az-agykutatok-magara-a-kivancsisagra-is-kivancsiak/
Néhány cikk a prediktív kódolással kapcsolatban
https://agykutatasegyszeruen.hu/2020/10/29/a-felderites-kiaknazas-dilemma/
https://agykutatasegyszeruen.hu/2020/03/19/az-ovtekerveny-mukodese/
Hivatkozások listája.
1. Friston, K. The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138 (2010).
2. Friston, K. Does predictive coding have a future? Nat. Neurosci. 21, 1019–1021 (2018).
3. van Kesteren, M. T. R., Ruiter, D. J., Fernández, G. & Henson, R. N. How schema and novelty augment memory formation. Trends Neurosci. 35, 211–219 (2012).
4. Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36, 181–204 (2013).
5. Quent, J. A., Henson, R. N. & Greve, A. A predictive account of how novelty influences declarative memory. Neurobiol. Learn. Mem. 179, 107382 (2021).
6. Frank, D. & Kafkas, A. Expectation-driven novelty effects in episodic memory. Neurobiol. Learn. Mem. 183, 107466 (2021).
7. Schomaker, J. & Meeter, M. Short- and long-lasting consequences of novelty, deviance and surprise on brain and cognition. Neurosci. Biobehav. Rev. 55, 268–279 (2015).
8. Barto, A., Mirolli, M. & Baldassarre, G. Novelty or Surprise? Front. Psychol. 4, (2013).
9. Rust, N. C. & Mehrpour, V. Understanding Image Memorability. Trends Cogn. Sci. 24, 557–568 (2020).
10. von Restorff, H. Über die Wirkung von Bereichsbildungen im Spurenfeld. Psychol. Forsch. 18, 299–342 (1933).
11. Wittmann, B. C., Bunzeck, N., Dolan, R. J. & Düzel, E. Anticipation of novelty recruits reward system and hippocampus while promoting recollection. NeuroImage 38, 194–202 (2007).
12. Lo, S. & Andrews, S. To transform or not to transform: using generalized linear mixed models to analyse reaction time data. Front. Psychol. 6, (2015).